
In unserem „BigData“ Projekt bei einem Automobilhersteller wurde das Deployment zu einem immer wichtigerem Punkt in der Entwicklung der Software. Durch den gestiegenen Umfang der Pakete und die diversen Umgebungen, verbunden mit dem Anspruch eine Umgebung von der Pike auf an einem Tag aufbauen zu können, wurde eine SCRUM Story „Deployment 2.0“ ins Leben gerufen.
Wie sah der bisherige Deploymentprozess aus?
Das Projekt umfasst diverse Technologien, die großen Gebiete waren:
- Oracle-Datenbank
- Informatica Workflows (IICS)
- Shell-Skripte zur Steuerung und z.B. Adressvalidierung
- APEX als Oracle GUI
- Die Scheduling Software Control-M
Das Deployment der einzelnen Komponenten erfolgte bisher mit einem Shell-Skript, da es sich um eine Unix-Umgebung handelt. Das bedeutet, dass die Konfiguration in einem Steuerungsfile stattfand, und zum Startzeitpunkt das Start-Skript manuell gestartet und die Ausführung live überwacht werden musste.
Dies war fehleranfällig und auch sehr eingeschränkt in der parallelen Ausführung. Die Fehlersuche gestaltete sich ebenso als schwierig. Aber vor allem konnte der Prozess nur von einer Person an einem Rechner überwacht werden.
Unser Lösungsansatz
Mit der Umstellung der Scheduling Software von Control-M auf Automic (UC4) kam die Idee auf, gleichzeitig das gesamte Deployment-Verfahren ebenfalls zu automatisieren und auf die neuen Anforderungen (z.B. GIT als Versionierungstool) anzupassen.
Die Pakete mussten nicht nach jedem Entwicklungsschritt manuell erstellt und angepasst werden, das Sprint-Deployment (Stichwort SCRUM) sollte komplett über Tags gesteuert werden.
Die Überwachung sollte von mehreren Personen ausführbar sein und die Benachrichtigung bei Fehlern sollte auch automatisch erfolgen.
Unsere Umsetzung
Zuerst wurde das Jobnetz auf dem Zeichenbrett als Schablone grob aufgeteilt. Im folgenden Bild, welches die Endversion der kompletten Umsetzung des Deployments darstellt, sieht man die Aufteilung der jeweiligen Schritte.
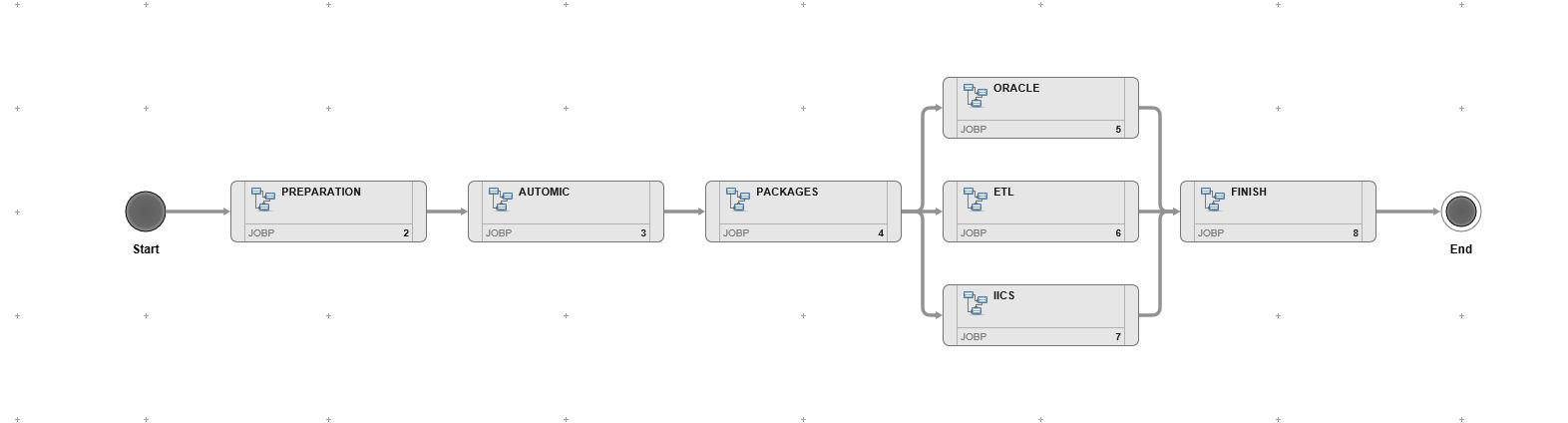
Als Erstes wurde ein Skript geschrieben, mit dem die Steuerung der jeweiligen auszurollenden Pakete behandelt wurde, die Gruppe „Preparation“ im Bild. Hierzu bediente man sich der GIT API, welche genau solche Szenarien vorsieht und die jeweiligen Schritte abhandelt. So konnte man sprintweise Pakete bauen und diese immer wiederholgenau hinstellen. Zudem wurden alle für das jeweilige Deployment relevanten Informationen gesammelt.
Als Zweites wurde die Aktualisierung der Jobnetze eingeplant, Gruppe „Automic“ im Bild. Mit den nun vorliegenden Informationen wurden die Pakete aus GIT extrahiert und jeweils für die kommenden Technologie-Stränge (Gruppe „Packages“ im Bild) aufgeteilt. Die Pakete wurden jeweils in einer parallelen Ausführung eingeplant. So konnte zum einen Zeit eingespart werden, zum anderen war im Fehlerfall sichergestellt, dass nicht das komplette Deployment wiederholt werden musste, sondern nur der fehlerhafte Teil.
In der letzten Gruppe „Finish“ wurden die Umgebungen aufgeräumt, die Logs ins jeweilige Archiv verschoben und das Deployment als erfolgreich in der Datenbank gekennzeichnet. Die Steuerung erfolgte nicht über Files, sondern über eine dafür angelegte Tabelle in der Projekt-Datenbank. So konnten die Informationen auch extrahiert und in einer GUI angezeigt werden – für den schnellen Überblick über die jeweilige Umgebungen (DEV / TEST / PROD) mit den entsprechenden Software-Versionen sowie anderen gewünschten Informationen.