
Heutzutage basieren die meisten von uns eingesetzten Anwendungen auf einer so genannten 3-Tier-Architektur. In diesem Artikel werden wir einen genaueren Blick auf diese Architektur und den am häufigsten verwendeten Technologie-Stack werfen.
Zunächst soll der Begriff “Tier” geklärt werden, der sich auf die physische Struktur bezieht und nicht mit “Layer” zu verwechseln ist, der eine logische Trennung des Codes darstellt.
Die Unterteilung einer Anwendung in Schichten ermöglicht unserer Software eine lose Kopplung, bessere Sicherheit und Skalierbarkeit.
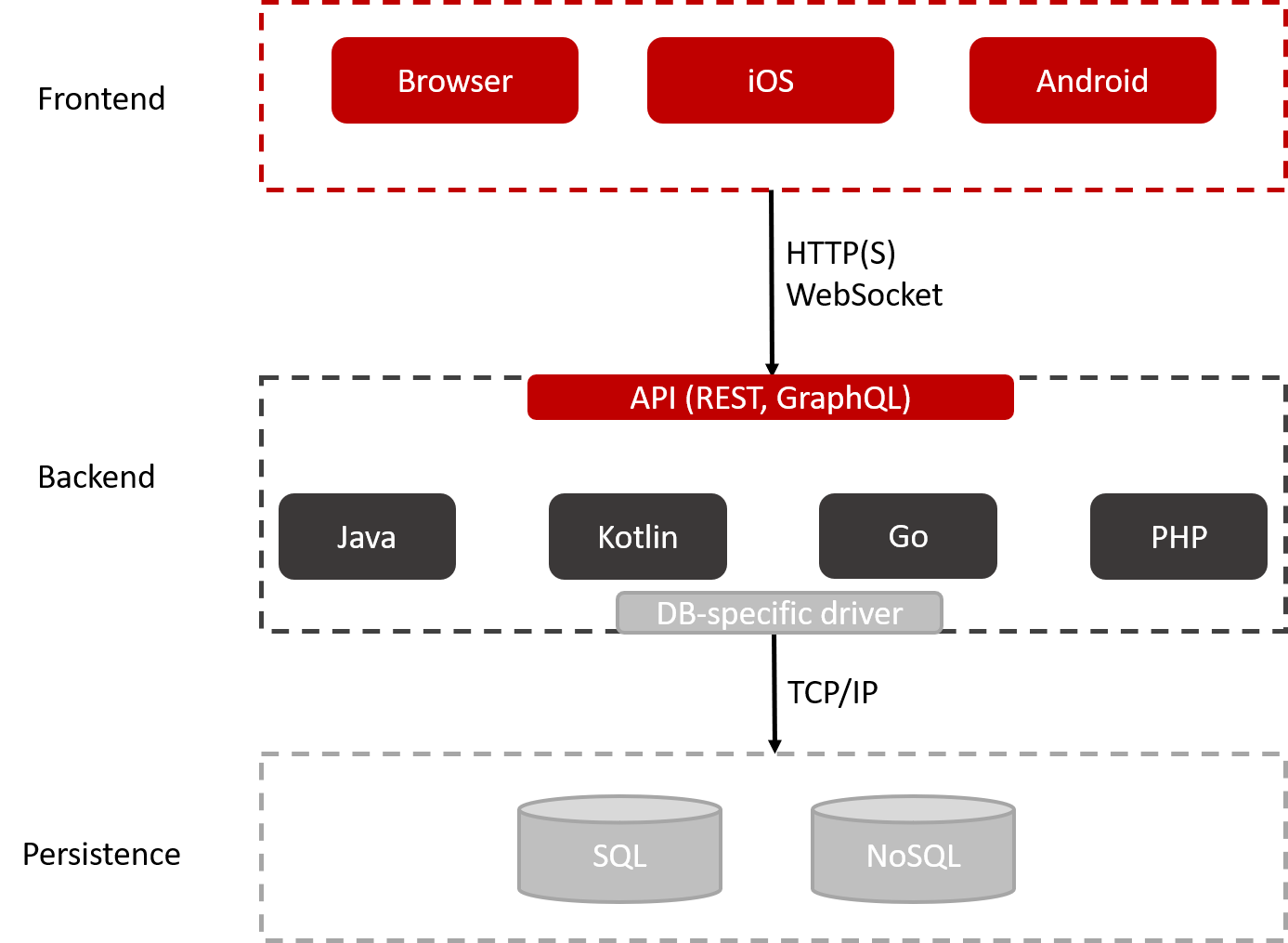
Übersicht der 3-Ebenen Architektur
Frontend-Ebene
Das Frontend wird auch als Benutzeroberfläche (UI) bezeichnet und stellt das dar, was ein Benutzer sieht und womit er interagiert. Diese Ebene besteht oft aus einer Webapp für browserbasierten Zugriff (Chrome, Edge, Firefox) und nativen Apps wie Android und iOS. Diese Clients kommunizieren mit dem Backend Tier meist über HTTP(S) und/oder ein WebSocket-Protokoll.
Eine Web-App wird normalerweise mit einem JavaScript-Framework erstellt: React, Angular, Vue und Svelte sind einige der bekanntesten davon.
Die Entwicklung von nativen Android-Apps erfordert die Entwicklungswerkzeuge von Google: Kotlin, Android Studio, Play Store. Für die Entwicklung nativer iOS-Apps sind die Entwicklungstools von Apple erforderlich: Swift, Xcode, App Store. Es gibt aber auch plattformübergreifende Frameworks, die helfen, den Entwicklungsprozess zu beschleunigen: Flutter, Reactive Native, Vue Native, von denen die meisten JavaScript nutzen, um Apps zu entwickeln, die unabhängig vom Betriebssystem sind und sowohl auf Android als auch auf iOS laufen.
Backend-Ebene
Die Backend-Ebene wird häufig mit einer Allzwecksprache wie Java, Kotlin, Go, Python oder PHP implementiert, um nur einige zu nennen. Diese Schicht stellt die Geschäftslogik der Anwendung dar. Sie setzt Geschäftsregeln durch und legt fest, wie Objekte miteinander interagieren. Ihre Aufgaben sind zum Beispiel: Kontrolle der Ausführungsreihenfolge, Berechnungen und Kalkulationen, Transaktionsmanagement, Komposition von Diensten und vieles mehr.
Außerdem muss es die Kommunikation zwischen Frontend und Backend ermöglichen. Das Backend muss eine API anbieten. REST oder GraphQL sind zwei gängige Methoden, um Backend-APIs zu entwerfen. Auf diese APIs kann über HTTP(S) für eine auf Client-Anfragen basierende Kommunikation oder über WebSocket für eine Vollduplex-Echtzeit-TCP-Kommunikation zugegriffen werden.
Einige der beliebtesten Frameworks zum Aufbau von Backend-Systemen sind Spring Boot (Java, Kotlin), Express NodeJS (JavaScript) oder Gin (Go).
Sobald die Client-Anfrage verarbeitet ist, muss der Zustand unserer Anwendung persistiert werden. An dieser Stelle kommt ein datenbankspezifischer Treiber ins Spiel. Er abstrahiert und vereinfacht die Kommunikation zwischen unserem Backend und unserer Persistenzschicht. Auf diese Weise müssen wir das Rad nicht jedes Mal neu erfinden und uns um alle technischen Details auf niedriger Ebene kümmern.
Persistence-Ebene
Hier werden die Daten gespeichert. Es gibt eine Vielzahl von Datenbanktechnologien. Im Großen und Ganzen können wir sie jedoch in zwei Kategorien einteilen: strukturierte Daten (SQL) und unstrukturierte Daten (NoSQL). Die Wahl hängt wirklich von den Anforderungen der Anwendung ab, denn jede Technologie hat ihre Vor- und Nachteile.
Einige beliebte Vertreter für NoSQL-Datenbanken sind MongoDB, CouchDB, Redis, Neo4J. PostgreSQL, MySQL, DB2, OracleDB sind einige der bekannten SQL-Datenbanken.
In diesem Artikel haben wir die Struktur einer modernen 3-Tier-Architektur untersucht und wie die einzelnen Schichten miteinander kommunizieren. Darüber hinaus haben wir auch einige beliebte Technologien genannt, die für den Aufbau solcher Systeme verwendet werden.