
Bei einem unserer Kunden im Automobilsektor kam die Anforderung auf, eine Volltextsuche auf eine relationale Oracle-Datenbank zu implementieren. Es sollten verschiedene Treffer, gewichtet nach sog. „Scores“, als Ergebnis geliefert werden.
Das vorhandene System ist eine Oracle-DB (DataVault-Architektur). Ein kompletter Kontakt-Datensatz erfordert somit einen Join über mehrere Tabellen.
Als mögliche Technologien für den Einsatz wurden zum einen die Bordmittel von Oracle betrachtet, zum anderen auch alternative Lösungen evaluiert. Da der Kunde einen starken Focus auf Free and Open Source Software (FOSS) Komponenten legt, wurde für die Umsetzung dieser Anforderung die Opensearch-Suite ausgewählt.
Überblick Opensearch
Opensearch ist eine verteilte Open Source Such- und Analyse-Suite, die ein hochgradig skalierbares, hochverfügbares System für den schnellen Zugriff auf große Datenmengen ermöglicht. Opensearch basiert auf der Suchbibliothek Apache Lucene und ist ein Branch von Elasticsearch 7.10.2.
Opensearch wurde als Fork der letzten ALv2-Version (Apache License version 2) von Elasticsearch weiterentwickelt, nachdem die Lizensierungs-Strategie der Elastic NV geändert wurde.
Die Opensearch Suite besteht im Wesentlichen aus drei Komponenten:
– Logstash, ein ETL-Tool, wird genutzt um Daten zu importieren.
– Opensearch analysiert/ indiziert/ speichert die Daten und stellt die eigentliche Suchmaschine zur Verfügung.
– Opensearch-Dashboard stellt Visualierungs- und Managementwerkzeuge zur Verfügung.
Projektumsetzung
Systemarchitektur
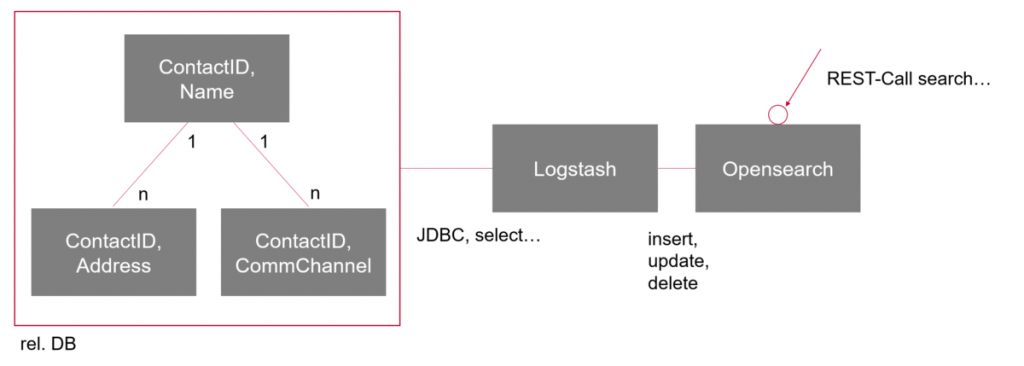
Die Anforderungen wurden folgendermaßen umgesetzt:
– Logstash importiert per JDBC (Java Database Connectivity) via Oracle-Select auf die relationale (rel.) DB regelmäßig alle bzw. neue Kontakte. Mittels eines Persistenz-Markers merkt sich Logstash, bis „wohin“ dieser Job bereits erledigt ist, so dass nach dem initialen Laden nur noch Deltas berücksichtigt werden.
– Innerhalb der Logstash-Pipeline können einzelne Felder manipuliert und gefiltert werden.
– Der Export von Logstash transferiert die Daten zu Opensearch, welches diese „indiziert“ und den REST (Representational State Transfer)-Web-Service-Endpunkt der Suchmaschine bereitstellt.
Besonderheiten
Folgende Besonderheiten sind zu beachten:
– Analyse und Aufbereitung der zu indizierenden Daten und der Suchanfrage: Sucht man z.B. nach MuelLeR, so erwartet man „müller“, „Müller“, „mueller“ usw. Dies kann man in Opensearch durch länderspezifische Indizes erreichen, auf die man unterschiedliche Templates mit verschiedenen Analysewerkzeugen anwendet. Diese zerlegen die Daten in einzelne Begriffe, Umlaute werden normiert, die Benutzung von Synonymen wird ermöglicht, das „Stemming“ wird durchgeführt („ging“ wird z.B. in „gehen“ umgewandelt, damit man nach allen Beugungsformen von „gehen“ suchen kann).
– Aktualität des Indexes: Löscht man in der relationalen DB Kontakte, so sind diese zunächst noch im Suchindex von Opensearch zu finden. D.h. man benötigt evtl. verschiedene Logstash-Pipelines, die sich um die Anwendungsfälle Insert und Delete kümmern. Ziel ist selbstverständlich, dass der Suchindex ein aktuelles Abbild des Datenbestandes der relationalen Datenbank enthält.